详细分析在大模型会话过程中使用的SSE模式
SSE(Server-Sent Events)是大模型流式输出的核心机制。下面从协议层到应用层做一次完整的分析。
一、为什么 LLM 选择 SSE
大模型推理的核心特性决定了它与 SSE 天然契合:token 是逐步生成的,整个响应可能耗时数秒到数十秒,而用户不可能等待完整响应再渲染。SSE 提供了一种极简的单向推送机制——服务器通过一条普通的 HTTP 连接持续写入数据,客户端实时消费,无需 WebSocket 的握手开销,也无需轮询的带宽浪费。
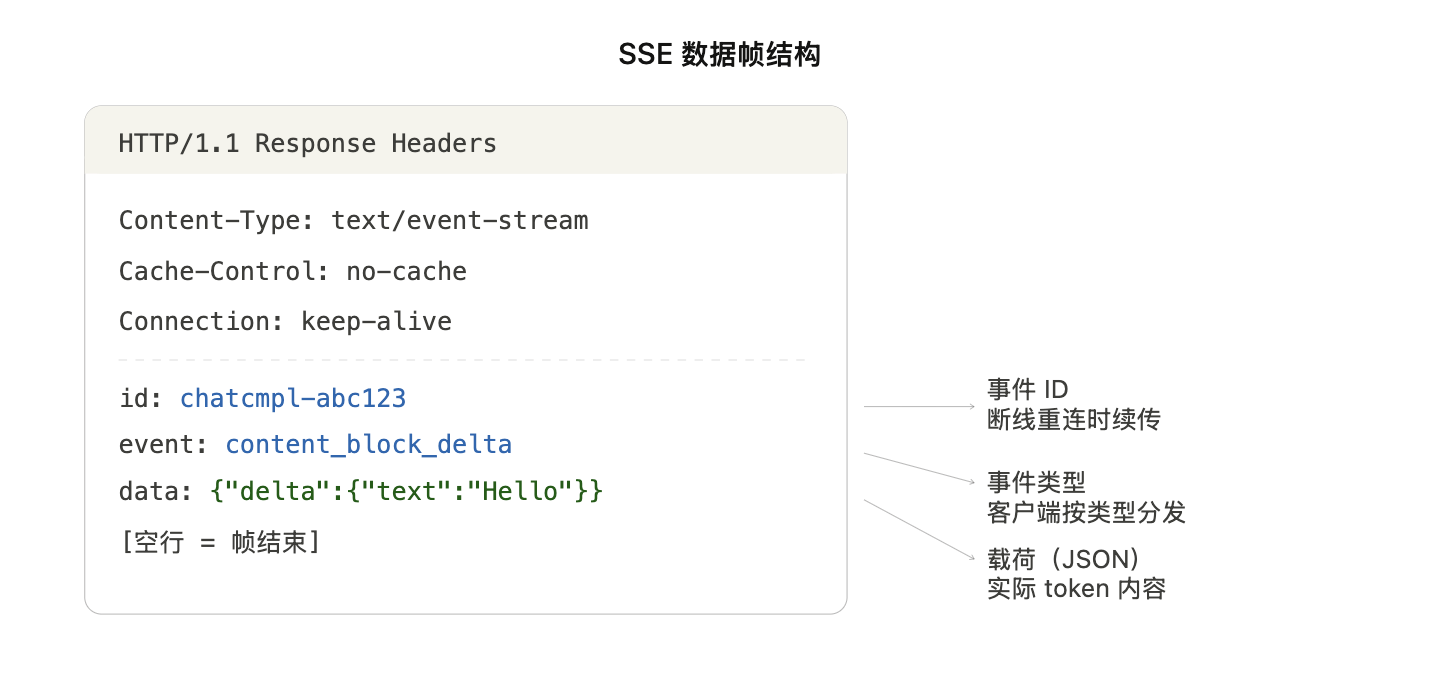
二、完整的请求-响应生命周期
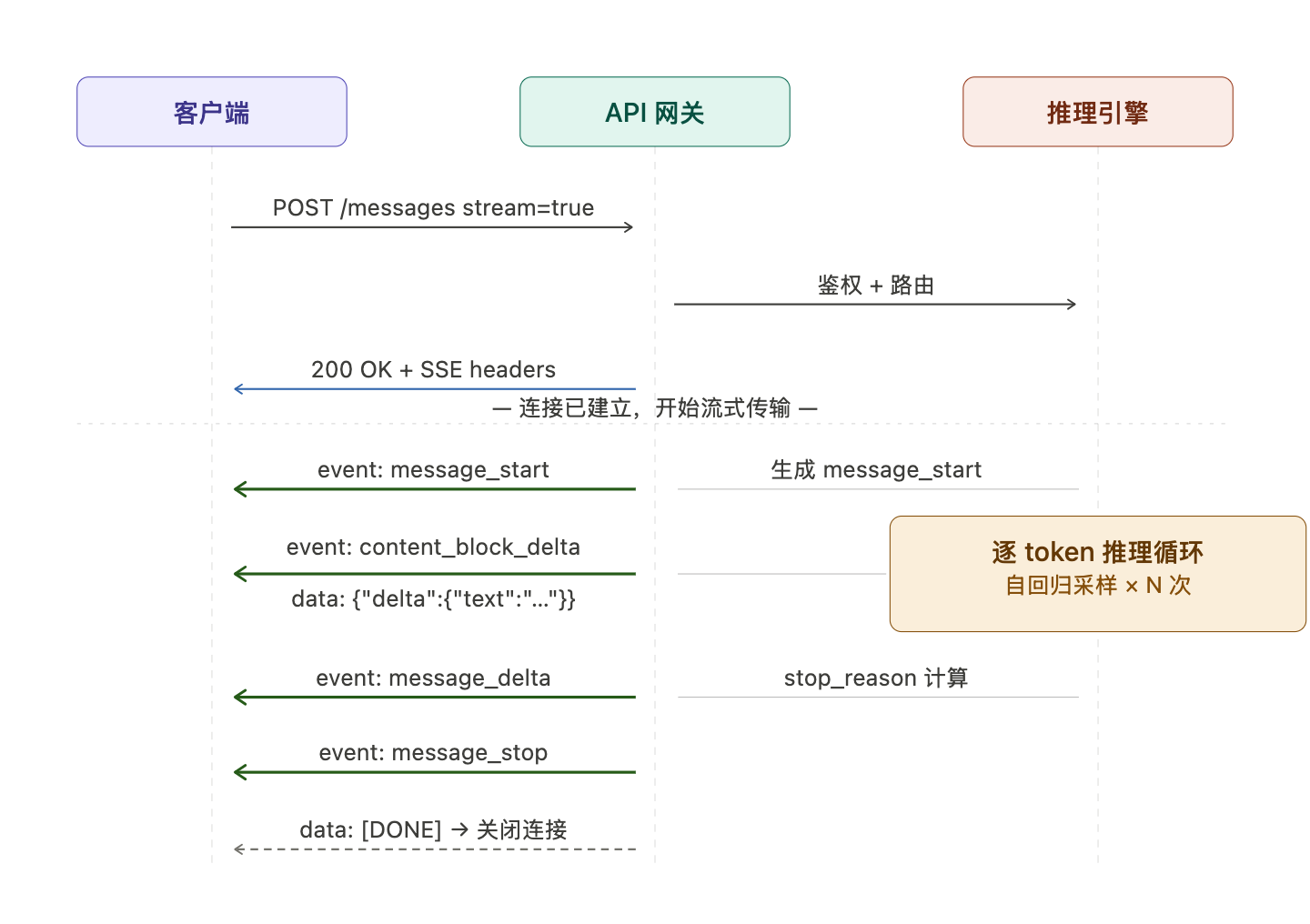
三、Anthropic API 的事件类型体系
以 Claude API 为例,它定义了一套层次化的事件协议,粒度比 OpenAI 的 choices[0].delta 更细。完整事件顺序如下:
message_start → content_block_start → content_block_delta(× N) → content_block_stop → message_delta → message_stop
每类事件的载荷语义不同:message_start 携带请求级元数据(model、id);content_block_delta 是真正的 token 载荷,type 字段区分文本增量(text_delta)与工具调用增量(input_json_delta);message_delta 在流末携带 stop_reason 和 token 用量统计。
这套设计使客户端可以在不缓冲完整响应的前提下做增量 UI 更新,同时 content_block 的分层抽象为多模态、tool use 等场景提供了扩展点。
四、客户端消费模式

五、关键工程细节
背压与缓冲:推理引擎产出 token 的速度通常快于网络传输,TCP 层会自然形成背压。但当客户端的 read() 调用速率低于服务器写入速率时,浏览器内核会缓冲未消费的 chunk,需关注内存占用。
断线重连与 Last-Event-ID:SSE 协议内置断线重连语义——客户端的 EventSource 会自动在重连请求头中携带 Last-Event-ID,服务器可据此从上一个已确认的事件继续推送。LLM 场景中实现这一机制的成本较高(需要服务端存储流状态),多数厂商选择让客户端从头重新请求。
event 字段 vs 仅用 data:OpenAI 格式几乎不用 event 字段,所有事件都用 data: {...} 携带类型标识;Anthropic 则充分利用 event 字段做一级分发,使客户端可以用 addEventListener('content_block_delta', ...) 精准订阅。两种风格各有取舍,后者更符合 EventSource 规范的设计意图。
data: [DONE] 哨兵:流结束的标志不是 HTTP 连接关闭(那是 error 场景),而是一个约定的哨兵帧 data: [DONE]。客户端应在收到此帧后主动关闭 reader,而不依赖网络层的 EOF,否则在反向代理场景下连接关闭时机不可预测。
工具调用(Tool Use)下的 SSE:当模型输出工具调用时,content_block_delta 的 type 变为 input_json_delta,携带 JSON 参数的增量片段。客户端需要对这些片段做流式 JSON 拼接,直到 content_block_stop 后才能拿到完整的工具调用参数并执行。这是流式与工具调用交叉时最容易出错的环节。
六、SSE vs WebSocket vs HTTP/2 Push
| 维度 | SSE | WebSocket | HTTP/2 Push |
|---|---|---|---|
| 方向性 | 单向(服务端→客户端) | 全双工 | 单向(服务端→客户端) |
| 协议复杂度 | 极低,纯文本 | 需要握手升级 | 需 HTTP/2 支持 |
| LLM 适配 | 天然契合(输出是单向流) | 过度设计 | 代理支持差 |
| 断线重连 | 协议内置 | 需手动实现 | 无标准机制 |
| 代理穿透 | 良好 | 部分代理有问题 | 反向代理支持有限 |
LLM 会话本质上是一个 request-streaming-response 模式——客户端发送一次完整请求,服务端持续流式应答——SSE 对这个模式的匹配程度几乎是最优的。WebSocket 的全双工能力在此场景中是浪费,却带来了更高的实现与运维成本,因此主流 LLM API(OpenAI、Anthropic、Google Gemini)均选择 SSE 作为流式传输方案。